Download the notebook here!
Interactive online version: ![]()
[1]:
from functools import partial
import statsmodels.formula.api as smf
import pandas as pd
import numpy as np
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import cross_val_score
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import LeaveOneOut
from auxiliary import plot_bandwidth
from auxiliary import plot_logistic
Regression Discontinuity Design (RDD)
In the problem set we are going to practice RDD in the Lee (2008) framework. We employ the original simplified data set on the individual candidates for the US House of Representatives from 1946 to 1998. If a candidate obtains more votes than his or her competitors, he or she takes the office. Each elected candidate represents one of 435 congressional districts. The elections are held every two years. We seek the answer to the question whether winning the election has a causal influence on the probability that the candidate will win the next election.
The observations of the data set individ_final.dta are clustered by district and election year. It consists of the following variables:*
outcome is a treatment variable; it is coded as 1 if a candidate won the election in the corresponding year and 0 – otherwise.
outcomenext is an outcome variable. It is coded as 1 if a candidate won the next election; as 0 if he or she did not win the next election; and as -1 if he or she did not participate in the next election.
difshare is an assignment variable; it is the winning candidate’s vote share minus the vote share of the highest performing competitor. Therefore, 0 is the cutoff point: a candidate whose vote share is more than 0 is automatically assigned to treatment.
[2]:
df = pd.read_stata("data/individ_final.dta")
df.index.set_names("Identifier", inplace=True)
df.head()
# Better handling of missing values
df.replace({"outcomenext": {-1: np.nan}}, inplace=True)
Task A
What is the main assumption that makes RDD possible? Define the local randomization condition in the simplified setup presented in the lecture.
Main assumption: agents are unable to precisely control the assignment variable near the known cutoff what leads to the randomized variation in treatment near the threshold.
The framework:
where: - Y is the outcome of interest, - D is the binary treatment indicator, - W is the vector of all predetermined and observable characteristics of the individual that might impact Y and/or X, - X is the assignment variable, - c is the cutoff value
Individuals have imprecise control over X when conditional on W = w and U = u, the density of V (and hence X) is continuous.
Definition of Local Randomization: If individuals have imprecise control over X, then Pr[W = w,U = u|X = x] is continuous in x: the treatment is “as good as” randomly assigned around the cutoff.
Task B
A major advantage of the RD design over competing methods is its transparency, which can be illustrated using graphical methods. A standard way of graphing the data is to divide the assignment variable into a number of bins, making sure there are two separate bins on each side of the cutoff point. Then, the average value of the outcome variable can be computed for each bin and graphed against the mid-points of the bins.
Task B.1
Create a new variable that groups the assignment variable values into 400 bins with a size of 0.005.
[3]:
df["bin"] = pd.cut(df["difshare"], 400, labels=False) / 200 - 1
df.sort_values(by="bin", inplace=True)
df.head()
[3]:
| year | outcome | outcomenext | difshare | bin | |
|---|---|---|---|---|---|
| Identifier | |||||
| 18052 | 1960 | 0 | NaN | -0.997953 | -1.0 |
| 16649 | 1946 | 0 | NaN | -0.999208 | -1.0 |
| 16651 | 1950 | 0 | NaN | -0.999915 | -1.0 |
| 16653 | 1952 | 0 | NaN | -0.997832 | -1.0 |
| 16655 | 1954 | 0 | NaN | -0.999943 | -1.0 |
Task B.2
Since we are interested in a causal influence on the probability that the candidate will win the next election based on winning the current election, drop the rows that do not have a comparable next election.
How many missing values do we have?
[4]:
df["outcomenext"].isna().sum()
[4]:
16403
Now get rid of all those observations.
[5]:
df.dropna(inplace=True)
np.testing.assert_equal(df["outcomenext"].isna().sum(), 0)
We can now build our remaining pipeline under the assumption that there are no missing values included. However, we might introduce them later again by some accidental operatoin. That is where data validation packages such as pandera come in handy. pandera allows to specify and check properties on your data easily .. and thus frequently.
Task B.3
Find the mean of the outcome variable for each bin or, in other words, local average. Draw this relationship on the scatterplot.
[6]:
df.groupby("bin").mean()["outcomenext"].sort_index().plot()
[6]:
<AxesSubplot:xlabel='bin'>
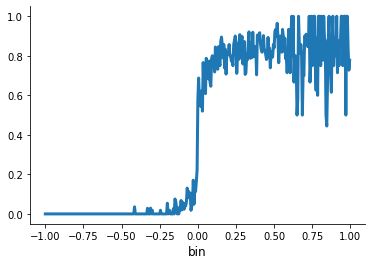
We will now repeatedly split the data at the cutoff.
[7]:
df["status"] = None
df.loc[df["difshare"].between(-0.25, +0.00), "status"] = "below"
df.loc[df["difshare"].between(+0.00, +0.25), "status"] = "above"
Task B.4
For better visuality we also add to the graph the fitted values of logistic regression around the cutoff. For this apply logistic regression separately on either side of the threshold (we take the bins with the share values from -0.25 to 0.25 and use the package LogisticRegression from sklearn.linear model). Extract probability estimates. Add them to the scatterplot in the proximity of cutoff. Do you observe a discontinuity at the cutoff point?
[8]:
probs = dict()
lr = LogisticRegression(C=1e20)
for label in ["below", "above"]:
df_subset = df.query(f"status == '{label}'")
y = df_subset["outcomenext"]
x = df_subset[["difshare"]]
lr.fit(x, y)
probs[label] = lr.predict_proba(x)
plot_logistic(df, probs)
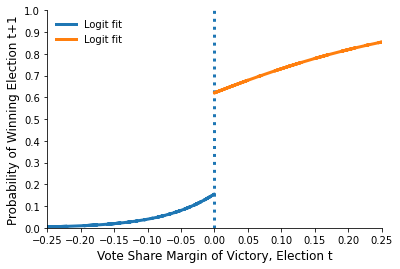
Task C
LLR as a method restricts the estimation to observations close to the cutoff. It is based on the assumption that regression lines within the bins around the cutoff point are close to linear. That helps to avoid some of the drawbacks of other parametric/non-parametrics approaches (Lee & Lemieux (2010))
*Run the LLR with a specification $Y = \alpha_r + \tau `D + :nbsphinx-math:beta X + :nbsphinx-math:gamma X D + :nbsphinx-math:epsilon $, where :math:`X is rectricted by a bandwidth: \(-h < X < h\). Interpret the result. Experiment with few bandwidths on your choice.*
[9]:
for h in [0.25, 0.2, 0.1, 0.05, 0.01]:
df_subset = df[df["difshare"].between(-h, h)]
formula = "outcomenext ~ outcome + difshare + difshare*outcome"
rslt = smf.ols(formula=formula, data=df_subset).fit()
info = [h, rslt.params[1] * 100, rslt.pvalues[1]]
print(" Bandwidth: {:>4} Effect {:5.3f}% pvalue {:5.3f}".format(*info))
Bandwidth: 0.25 Effect 52.439% pvalue 0.000
Bandwidth: 0.2 Effect 49.521% pvalue 0.000
Bandwidth: 0.1 Effect 43.861% pvalue 0.000
Bandwidth: 0.05 Effect 38.910% pvalue 0.000
Bandwidth: 0.01 Effect 25.700% pvalue 0.069
Task D
As you might find, the treatment effect result is sensitive to the bandwidth choice. In general, choosing a bandwidth in estimation involves finding an optimal balance between precision and bias. One the one hand, using a larger bandwidth yields more precise estimates as more observations are available to estimate the regression. On the other hand, the linear specification is less likely to be accurate (Lee & Lemieux (2010)).
We are going to review one of the approaches for choosing a bandwidth – cross-validation “leave one out” procedure. The main idea is to take an observation i in the data, leave it out, run LLR, and use the estimates to predict the value of \(Y\) at \(X = X_i\). Proceeding with each observation separately on each side of the cutoff, we obtain the predicted values of \(Y\) that can be compared to the actual values. The optimal bandwidth is then a value of \(h\) that minimizes the mean square of the difference between the predicted and actual values of \(Y\). And overall mean square error is simply the average of the squares of the prediction errors on each side of the cutoff.
Draw the graph showing the relationship between the bandwidth and the mean square error. What is the optimal bandwidth for LLR in our framework?*
[10]:
num_points = 10
bandwidth = np.linspace(0.01, 0.50, num_points)
scoring = "neg_mean_squared_error"
model = LinearRegression()
cv = LeaveOneOut()
cross_val_score_p = partial(cross_val_score, scoring=scoring, cv=cv)
We are ready to now run the actual computations.
[11]:
rslts = pd.DataFrame(columns=["below", "above", "joint"])
rslts.index.set_names("Bandwidth", inplace=True)
for label in ["below", "above"]:
for h in bandwidth:
if label == "below":
df_subset = df.loc[df["difshare"].between(-h, +0.00)]
else:
df_subset = df.loc[df["difshare"].between(+0.00, +h)]
y = df_subset[["outcomenext"]]
x = df_subset[["difshare"]]
rslts.loc[h, label] = -cross_val_score_p(model, x, y).mean()
rslts["joint"] = rslts[["below", "above"]].mean(axis=1)
It is time for a visual inspection.
[12]:
plot_bandwidth(bandwidth, rslts["joint"])
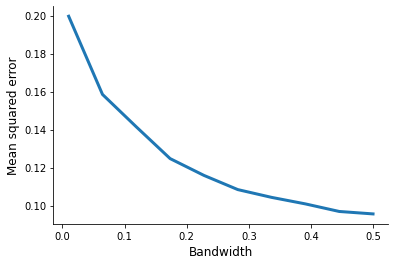
What is the optimal bandwith in this setting?
[13]:
print(f" Optimal bandwidth: {rslts['joint'].idxmin():5.3f}")
Optimal bandwidth: 0.500
References
Lee, D. S. (2008). Randomized experiments from non-random selection in US house elections. Journal of Econometrics, 142(2), 675–697.
Lee, D. S., & Lemieux, T. (2010). Regression discontinuity designs in economics. Journal of Economic Literature, 48, 281-355.